Multiplayer AlphaZero – arXiv Vanity
Por um escritor misterioso
Descrição
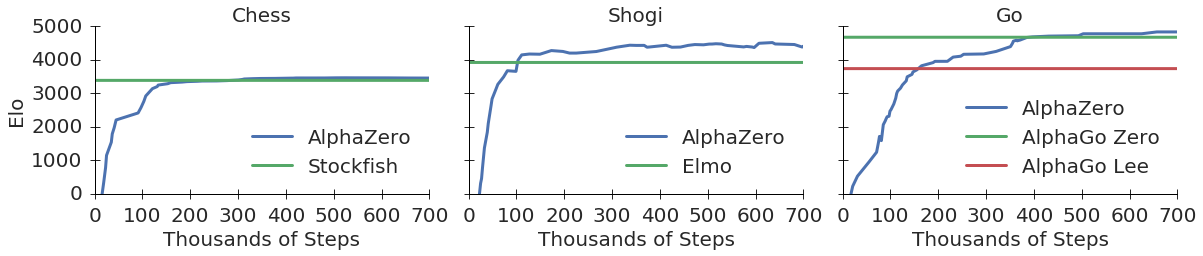
The AlphaZero algorithm has achieved superhuman performance in two-player, deterministic, zero-sum games where perfect information of the game state is available. This success has been demonstrated in Chess, Shogi, and Go where learning occurs solely through self-play. Many real-world applications (e.g., equity trading) require the consideration of a multiplayer environment. In this work, we suggest novel modifications of the AlphaZero algorithm to support multiplayer environments, and evaluate the approach in two simple 3-player games. Our experiments show that multiplayer AlphaZero learns successfully and consistently outperforms a competing approach: Monte Carlo tree search. These results suggest that our modified AlphaZero can learn effective strategies in multiplayer game scenarios. Our work supports the use of AlphaZero in multiplayer games and suggests future research for more complex environments.

Philosophers ought to develop, theorize about, and use
Overview, Get ready to slay all day in our SlayStation® 2.0 Tabletop and SlayStation Drawers! This bundle features our SlayStation 2.0 tabletop that

SlayStation 2.0 Tabletop + 4 Drawer Units Bundle

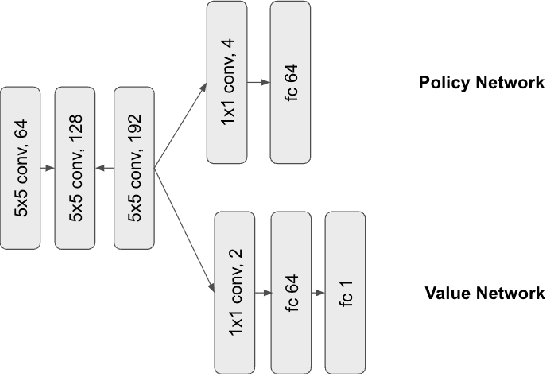
Deep Reinforcement Learning – arXiv Vanity

Generation Zero® - Tubular Vanity Pack on Steam

Books: profit motive

Starfinder Society Scenario #1-98: Into the Perplexity

Multiplayer AlphaZero – arXiv Vanity
Unusual Oozyo Probe - No Man's Sky Wiki

Combining Deep Reinforcement Learning and Search for Imperfect
de
por adulto (o preço varia de acordo com o tamanho do grupo)